





δυστηχως ομως ξερουμε ηδη απο πρωτο χερι οτι δεν ειναι rdna 2 ειναι rdna 1 με rt function και ενα δικο τους direct storage system τα νουμερα τους ειναι εντελως αχρηστα
Εμφάνιση 256-270 από 485
-
03-11-20, 09:29 Re: Γενικη συζητηση για επεξεργαστες #256

 Eminent Member
Eminent Member

- Εγγραφή
- 01-11-2011
- Μηνύματα
- 3.617
- Downloads
- 0
- Uploads
- 0
- ISP
- HOL

-
03-11-20, 16:44 Re: Γενικη συζητηση για επεξεργαστες #257
 Banned
Banned
- Εγγραφή
- 30-04-2008
- Μηνύματα
- 8.650
- Downloads
- 0
- Uploads
- 0
Nah, δεν μπορεί να γίνει integrate RT function τόσο εύκολα σε RDNA1. Ο Cerny είπε ότι το PS5 έχει features από RDNA3 (όπως το PS4 είχε 8 ACEs, δηλαδή feature της μεταγενέστερης GCN 1.1). Δες όλη την παρουσίαση. Αρχικό μήνυμα από konig
Αρχικό μήνυμα από konig

Επίσης, αυτά που λέει η MS περί "full" RDNA2 δεν ισχύουν, αφού δεν υπάρχει Infinity Cache. Για το PS5 ίδωμεν, δεν υπάρχει chip diagram ακόμα. Πάντως insiders που πέσανε μέσα για την Infinity Cache (ούτε εγώ το πίστευα) λένε ότι θα έχει και το PS5, ίσως κομμένη.
Ποιά νούμερα είναι άχρηστα;
- - - Updated - - -
https://twitter.com/chiakokhua/statu...90890874449920
-
04-11-20, 00:44 Απάντηση: Γενικη συζητηση για επεξεργαστες #258
.

- Εγγραφή
- 29-06-2005
- Μηνύματα
- 15.865
- Downloads
- 4
- Uploads
- 0
- ISP
- .
https://www.reddit.com/r/intel/comme...2020_is_edram/
Ευλογη απορια του αρθρογραφου: Αρχικό μήνυμα από σχολιο στο reddit
Και μετα λενε οτι ο λογος που δεν βαρανε μεγαλα IPC upgrades και τους ξεφτιλιζουν τα ARM ειναι οτι εχουν ηδη κοψει τα ωριμα φρουτα. Σαβουρες πουλανε συνεχεια.Fast forward to 2020, and we now have mature 14 nm and 7 nm processes, as well as a cavalcade of packaging and eDRAM opportunities. We might consider that adding 1-2 GiB of eDRAM to a package could be done with high bandwidth connectivity, using either Intel’s embedded multi-die technology or TSMC’s 3DFabric technology.
If we did that today, it could arguably be just as complex as what it was to add 128 MiB back in 2015. We now have extensive EDA and packaging tools to deal with chiplet designs and multi-die environments.
So consider, at a time where high performance consumer processors are in the realm of $300 up to $500-$800, would customers consider paying +$60 more for a modern high-end processor with 2 gigabytes of intermediate L4 cache? It would extend AMD’s idea of high-performance gaming cache well beyond the 32 MiB of Zen 3, or perhaps give Intel a different dynamic to its future processor portfolio.
As we move into more a chiplet enabled environment, some of those chiplets could be an extra cache layer.
Χωρις αυξηση σε L1/L2 caches, (ιδιες ή μικροτερες L3 γιατι πιανουν παρα πολυ die space) και μεγαλες cache (ή μικρη ποσοτητα HBM2/3) off-die, η αποδοση θα υστερει και 25-35% σε σχεση με αυτο που θα μπορουσε να ειναι.
-
04-11-20, 00:55 Re: Γενικη συζητηση για επεξεργαστες #259
Banned
- Εγγραφή
- 30-04-2008
- Μηνύματα
- 8.650
- Downloads
- 0
- Uploads
- 0
Κάπου είχα διαβάσει ότι αν μια σύγχρονη CPU (π.χ. Zen 2) δεν είχε το bottleneck της DDR4, θα χτύπαγε 600+ fps στο GTAV (προφανώς μόνο με τεράστια ποσότητα SRAM).
Δυστυχώς το memory wall είναι υπαρκτό πρόβλημα.
Αν έδιναν επιλογή στο BIOS (CPU) ή στους drivers (GPU) να γίνουν disable οι caches (L1/2/3), ακόμα καλύτερα με granular controls (π.χ. 0/2/4/8/16/32MB για L3), θα βλέπαμε πόσο ακριβώς δίνει ή κόβει σε επιδόσεις.
-
04-11-20, 01:28 Απάντηση: Re: Γενικη συζητηση για επεξεργαστες #260

 no eternal reward will forgive us now for wasting
no eternal reward will forgive us now for wasting

- Εγγραφή
- 29-05-2007
- Περιοχή
- δυο κλικ πιο κατω
- Ηλικία
- 48
- Μηνύματα
- 7.701
- Downloads
- 38
- Uploads
- 0
- Άρθρα
- 21
- Τύπος
- VDSL2
- Ταχύτητα
- 5000/1200
- ISP
- βρωμονταφον
- Router
- της hol
- SNR / Attn
- 8(dB) / 29(dB)
- Path Level
- Fastpath
χωρις να εχω κρατησει στοιχεια ή να εχω κανει προσεκτικη προσεγγιση λεπτομερειων ,ειχα περασει μια περιοδο δοκιμαζοντας επεξεργαστες με βαση την cache , και ειχε διαφορα απο το unplayable σε στρωτη ροη , με την παραπανω cache , ενω αν ανεβαζα το clock και 33% πανω ( σε εναν g3258 στα 4.2 gh z (1,5mb/core) ) δεν επιανε εναν e8400 (3mb/core) Αρχικό μήνυμα από uncharted
με 2mb/core και πανω , γινεται δουλεια
(το λεω cache και οχι l2 και l1 και l3 γιατι εκει καπου με τα smartcache σταματησα να την ψαχνω ,αλλα και δεν εφτασα σε βαθος την παρατηρηση )αντεχεις να αμφιβαλεις για ολα οσα εχεις διδαχτει ;
Cancel my subscription to the Resurrection. Send my credentials to the House of Detention
ο φασισμος ειναι ο νομος των δουλων
AV tip:να ακολουθεις αυτο που ψαχνεις , οχι αυτο που σε βρισκει .
-
04-11-20, 02:08 Re: Απάντηση: Re: Γενικη συζητηση για επεξεργαστες #261
Banned
- Εγγραφή
- 30-04-2008
- Μηνύματα
- 8.650
- Downloads
- 0
- Uploads
- 0
Για να το πούμε με απλά λόγια: η cache (SRAM) είναι όπως το συρτάρι στο γραφείο και η DRAM όπως η βιβλιοθήκη (ο σκληρός δίσκος είναι η αποθήκη/πατάρι). Αρχικό μήνυμα από badweed
Πάντα το συρτάρι είναι πιο μικρό σε μέγεθος, αλλά πιο εύκολα προσβάσιμο. Φυσικά μπορείς να έχεις γραφείο χωρίς συρτάρι, αλλά μετά θα έχεις πήγαινε-έλα στην βιβλιοθήκη...
Το λέω απλοποιημένα, γιατί υπάρχουν πολλαπλά επίπεδα caches. Και φυσικά οι GPUs ακολουθούν με καθυστέρηση τις CPUs όσο πιο programmable/general-purpose γίνονται.
Την ίδια στρατηγική ακολουθεί και η Apple για να υπερκεράσει το memory wall (το οποίο είναι και πιο έντονο στις LPDDR):
https://www.anandtech.com/show/14892...d-max-review/3
https://www.macworld.com/article/357...al-engine.html
Με την διαφορά ότι αυτή η system level cache είναι πραγματικά unified για όλους τους processors (CPU, GPU κλπ.), κάτι που δεν έχει επιτευχθεί ακόμα στις AMD/x86 APUs, μάλλον λόγω BC περιορισμών.
Όπως τα βλέπω τα πράγματα, στο απώτερο μέλλον (2030+) τα PC θα είναι all-in-one σε ένα package (CPU + GPU + RAM). Hassle-free (α λα κονσόλα), αλλά με περιορισμένο ή καθόλου upgradeability.
Το ιστορικό trend τις τελευταίες δεκαετίες δείχνει όλο και περισσότερο integration (κάποτε ακόμα και ο IDE controller ή η RTC battery ήταν σε discrete ISA cards).
Ήθελε να το κάνει παλιά η Intel στις CPUs, αλλά έκανε πίσω: https://www.extremetech.com/computin...-upgradable-pc
Resistance is futile όμως. Θα υπάρξει DDR6; Μιλάμε για το τελευταίο παράλληλο interface, όταν όλα τα άλλα έχουν γίνει serial προ πολλού (PCI -> PCIe, LPT -> USB, PATA -> SATA κλπ.)
Έχουν πολλά προβλήματα με συγχρονισμό και timings τα παράλληλα interfaces για να κάνουν scale up (προβλήματα με θόρυβο στο σήμα), για αυτό και τα περισσότερα έχουν εγκαταλειφθεί.
Η DDR και τα παρακλάδια της (LPDDR, GDDR) έχουν μείνει ως απομεινάρι, μιας και η αντίστοιχη serial RAM (Rambus) ενώ έχει πολλά τεχνικά πλεονεκτήματα (low pin count -> χαμηλότερο κόστος/PCB routing, μικρότερος memory controller -> περισσότερος χώρος στο chip για άλλα πράγματα), έχει αποκτήσει την ρετσινιά του patent troll η Rambus. Κάποτε πήγαν να το εφαρμόσουν στους Pentium 4, αλλά ήταν ακριβές αρχικά (δεν υπήρχε οικονομία κλίμακας όπως στις SDRAM) και λόγω πατεντών το σταμάτησαν.
-
05-11-20, 22:45 Re: Γενικη συζητηση για επεξεργαστες #262
Eminent Member
- Εγγραφή
- 01-11-2011
- Μηνύματα
- 3.617
- Downloads
- 0
- Uploads
- 0
- ISP
- HOL
μια χαρα μπορει δεν ειναι dedicated τα nws κανουν την δουλεια και εδω αλλωστε custom ειναι Αρχικό μήνυμα από uncharted
η ms μια χαρα τα λεει γιατι δεν φοραει big navi και ειναι 100% σιγουρο πως τα mid range δεν θα εχουν τετοιου ειδους cache
-
05-11-20, 22:50 Re: Γενικη συζητηση για επεξεργαστες #263
Banned
- Εγγραφή
- 30-04-2008
- Μηνύματα
- 8.650
- Downloads
- 0
- Uploads
- 0
Τι είναι τα NWS; Αρχικό μήνυμα από konig
Λέω ότι δεν μπαίνει έτσι απλά HW RT, μιας και παίζει βαθύτερο integration με τα TMUs. Δεν είναι απλά additional cores.
ΥΓ: Γενικά θα σου έλεγα να ψάχνεις καλύτερα τις πηγές σου, γιατί τα fake news πάνε σύννεφο. Από RDNA1 μέχρι κατά φαντασίαν υπερθέρμανση (με LM κιόλας).
-
06-11-20, 03:52 Απάντηση: Γενικη συζητηση για επεξεργαστες #264
.
- Εγγραφή
- 29-06-2005
- Μηνύματα
- 15.865
- Downloads
- 4
- Uploads
- 0
- ISP
- .
Ο anand εχει ψιλοκαλο coverage για τους zen3.
Παρατηρω οτι
-Load/Store zen1/zen2/skylake ειχαν 2/1 (2 read / 1 write per cycle),
-το icelake πηγε σε 2/2 (ειχα γραψει εδω για το οτι ειναι θετικο για το ice: https://www.adslgr.com/forum/threads...50#post6613150),
-zen3 πηγε σε 3/2.
Εντωμεταξυ ο zen einai 6-wide (μεχρι 6 ins/cycle processed) που σημαινει οτι επωφελειται παρα πολυ γιατι ηταν ...bottlenecked στα loads/stores. Ουσιαστικα αρση του bottleneck εγινε.
Επισης αλλο bottleneck που ειχα γραψει παλαιοτερα με καποια instructions τα εχουν φτιαξει.
https://www.anandtech.com/show/16214...5700x-tested/6
DIVS απο 46 cycles στο zen2 επεσε στα 20 (το icelake ηταν στα 18 - οπότε εκλεισε πολυ η ψαλιδα). Επισης σε αρκετες SSE/AVX εντολες εχει διπλασιαστει το throughput, κανει execute διπλασιες εντολες στον ιδιο χρονο. Αυτο ειναι σαν να λεμε επιδοσεις avx512 με ...avx2.
Δλδ αμα βγαλεις, λεμε τωρα, 2 εντολες που επεξεργαζονται 2 vectors 256bit σε 1 μοναδα χρονου, ειναι σαν να το εχεις κανει με 1 εντολη που επεξεργαζεται 1 vector 512 bit σε 1 μοναδα χρονου. Αυτο περα απο τη μειωση του FMA απο 5 κυκλους σε 4 (και αλλη βελτιωση εκει). Το προβλημα ειναι οτι δε το κανει σε ολες τις εντολες αλλα σε καποιες. Αλλα αν το κανεις σωστα τοτε κοντραρεις στα ισια avx512 με ...avx2 που βγαζει παραπανω avx2 throughput per cycle.
Αλλα για να μη ξεχνιομαστε, και επειδη υπαρχει ακομα πολυ δρομος για βελτιωση, η κατασταση γενικοτερα ειναι αυτη:
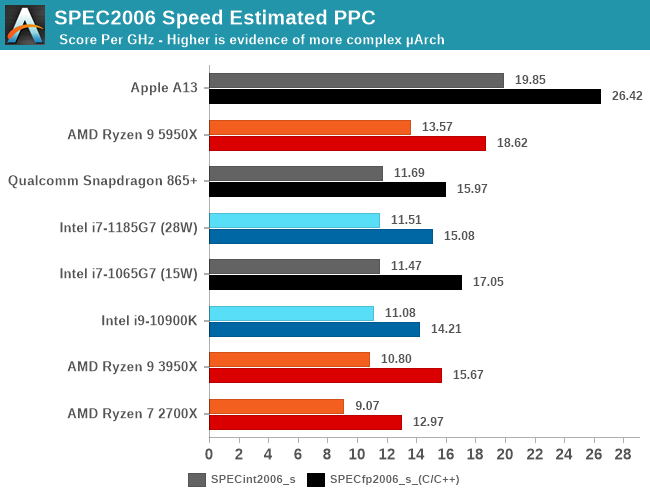
Το zen3 γενικοτερα ΠΟΛΥ καλυτερο απ'τις zen2/skylake σαβουρες... ξεμπουκωσε καλα με την επιδιορθωση καποιων bottlenecks. Θα ξεμπουκωσει κιαλλο αμα του δωσουν IMC (πχ APU) και μεγαλυτερες L1 caches.
-
06-11-20, 09:55 Απάντηση: Γενικη συζητηση για επεξεργαστες #265
 ...
aDSLgr Honouree
...
aDSLgr Honouree

- Εγγραφή
- 23-03-2004
- Ηλικία
- 56
- Μηνύματα
- 3.968
- Downloads
- 5
- Uploads
- 0
- Τύπος
- FTTH
- Ταχύτητα
- 102400/10240
- ISP
- Vodafone
- Router
- Vodafone PS 6
Πάντως απ' ότι φαίνεται η βελτίωση από τη προηγούμενη γενιά είναι πολύ μεγάλη, πρωτοφανής για την τελευταία 10ετία.

-
06-11-20, 12:43 Re: Γενικη συζητηση για επεξεργαστες #266
Eminent Member
- Εγγραφή
- 01-11-2011
- Μηνύματα
- 3.617
- Downloads
- 0
- Uploads
- 0
- ISP
- HOL
δεν εχει τιποτα dedicated η rdna για να κανει rt ολη την δουλεια την κανουν τα ace οπως παλια απλα τωρα εχουν την cache Αρχικό μήνυμα από uncharted
-
06-11-20, 19:47 Re: Γενικη συζητηση για επεξεργαστες #267
Banned
- Εγγραφή
- 30-04-2008
- Μηνύματα
- 8.650
- Downloads
- 0
- Uploads
- 0
Εχμ, πάλι μπερδεύεις ανόμοια πράγματα. Όπως είπα, τα ray accelerators της RDNA2 είναι deeply integrated μέσα στα TMUs, δεν μπαίνουν εκ των υστέρων σε μια RDNA1/RX 5700 λες κι είναι τουβλάκια LEGO. Αρχικό μήνυμα από konig
Καμία σχέση τα TMUs με ACEs (το PS4 με GCN 1.0 GPU δεν είχε 2 ACEs, αλλά 8 ACEs -> future GCN 1.1 feature). Αυτά είναι που δίνουν τον χαρακτηρισμό semi-custom design.
PS4 GPU: https://www.techpowerup.com/gpu-spec...-hd-7970m.c388
Εξού και γιατί μίλησαν για RDNA3 future proofness (ότι δηλαδή features του PS5 θα εμφανιστούν στην RDNA3 των PC αν κριθούν επιτυχημένα, όπως δηλαδή έγινε με τα 8 ACEs). Και η Polaris του PS4 Pro (RX 470-based) είχε Vega features (2xFP16/RPM), που δεν είχε η RX 470 των PC. Δεν είναι τόσο δύσκολο να δεις το pattern που περιγράφω, αρκεί να μελετήσεις προσεκτικά τι συμβαίνει σε βάθος πολλών ετών.
Επίσης, δεν είπαν (ακόμα) τίποτα για dedicated decompression ASIC στην RDNA2 των PC, οπότε θα υποθέσω ότι θα τρέχει στις shader ALUs (α λα Turing/Ampere). Αυτό με απλά λόγια σημαίνει ότι θα σου κόψει λίγο ή πολύ σε raster performance.
Ένα ASIC είναι dedicated στον ρόλο του (βλ. H.264/H.265/VP9/AV1) και δεν ρουφάει πόρους από τις ALUs για το decoding/encoding.
Επίσης έχει πολύ χαμηλό transistor count (το 10% συγκριτικά με έναν αντίστοιχο general purpose processor) και εξίσου χαμηλό TDP.
Εδώ τα εξηγεί μια χαρά: https://www.adslgr.com/forum/threads...=1#post6905347
Ο memory controller στις Intel CPUs έχει απευθείας σύνδεση με τα CPU cores, εξού και το χαμηλότερο latency. Αρχικό μήνυμα από MNP-10
Στις AMD CPUs όλο το memory traffic περνάει μέσα από το Infinity Fabric πρώτα, εξού και το αυξημένο latency (ακόμα και οι μονολιθικές Ryzen CPUs/APUs δεν πιάνουν νούμερα Intel).
Πάντα η Intel θα έχει αυτό το αβαντάζ, μέχρι να πάει κι αυτή σε ανάλογο mesh fabric για scalability (η κύρια αγορά είναι οι servers, μιας και οι x86 CPUs φτιάχνονται για εκεί πρωτίστως και μετά γίνονται trickle down προς desktop/laptop/home consoles).
Οι ARM από την άλλη φτιάχνονται από κάτω (mobile) προς τα πάνω (servers). Όπως και κάποιες GPUs (π.χ. Maxwell/tiled rasterizer).
-
07-11-20, 14:59 Απάντηση: Γενικη συζητηση για επεξεργαστες #268
.
- Εγγραφή
- 29-06-2005
- Μηνύματα
- 15.865
- Downloads
- 4
- Uploads
- 0
- ISP
- .
...Το μαθαμε και αυτο: Αρχικό μήνυμα από MNP-10
https://www.techarp.com/computer/amd-zen-3-tech-report/
AMD Zen 3 Transistor Count + Die Size
The new Zen 3 CCD has 4.15 billion transistors, with a die size of 80.7 mm². That’s up from the 3.8 billion transistors and a die size of 74 mm² for the Zen 2 CCD.
The Matisse-era IOD remains the same – 2.09 billion transistors, with a die size of 125 mm².They will both be manufactured using the same 7 nm TSMC process for CCD, and 12 nm Global Foundries process for IOD....ιδιο density zen2 και zen3 chiplets στα 51εκ τρανζιστορ/mm2, το ιδιο I/O die και τα 2.Core Die Zen 3 Zen 2 Process 7 nm TSMC Transistors 4.15 billion 3.8 billion Die Size 80.7 mm² 74 mm² I/O Die Zen 3 Zen 2 Process 12 nm GoFlo Transistors 2.09 billion Die Size 125 mm²
Μεσο density ενος 8 core zen3 συνυπολογιζοντας και το I/O, παει 6.24 δις τρανζιστορ απλωμενα σε ~205.7mm2, δλδ περι τα 30.3 εκ τρανζιστορς/mm2. To zen2 APU ειναι >60 για συγκριση (με το I/O και IMC ενσωματωμενα).
-
07-11-20, 15:07 Απάντηση: Γενικη συζητηση για επεξεργαστες #269
...
aDSLgr Honouree
- Εγγραφή
- 23-03-2004
- Ηλικία
- 56
- Μηνύματα
- 3.968
- Downloads
- 5
- Uploads
- 0
- Τύπος
- FTTH
- Ταχύτητα
- 102400/10240
- ISP
- Vodafone
- Router
- Vodafone PS 6
Χαλαρά το πάει η AMD.... 30.3mil/mm2, και για το CCD βγαίνει περίπου 50mil/mm2, πολύ πιο χαμηλά από τη τυπική πυκνότητα της TSMC, ισως έτσι βελτιώνει τα yields ακόμα περισσότερο. Αρχικό μήνυμα από MNP-10
-
07-11-20, 15:13 Απάντηση: Γενικη συζητηση για επεξεργαστες #270
.
- Εγγραφή
- 29-06-2005
- Μηνύματα
- 15.865
- Downloads
- 4
- Uploads
- 0
- ISP
- .
Και για εναν ακομα λογο: Η AMD εχει συμβολαιογραφικη υποχρεωση να απορροφαει dies απ'τη glofo ενω οταν παει σε 3ο fab οπως η tsmc παλι πληρωνει την glofo σε φαση διαφυγοντα κερδη (κατοπιν συμφωνιας βεβαια)... οπότε χρησιμοποιει glofo οπου μπορει...
 Παράθεση
Παράθεση
Bookmarks